Fragments and Consolidation¶
In this tutorial we will explain in more detail the concept of array fragments and introduce the basics of consolidation. It is strongly recommended that you read the tutorials on writing dense and sparse arrays first.
Program |
Links |
|
|

Basic concepts and definitions¶
Fragment
An array is composed of fragments. Each fragment is perceived as an array snapshot, containing only the cells written upon a write operation. TileDB distinguishes between dense and sparse fragments. A sparse array is composed only of sparse fragments, whereas a dense array can have both dense and sparse fragments. Each fragment is a timestamped, standalone subdirectory inside the array directory.
Consolidation
To mitigate the potential performance degradation resulting from the existence of numerous fragments, TileDB enables you to consolidate the fragments, i.e., merge all fragments into a single one.
What is a fragment?¶
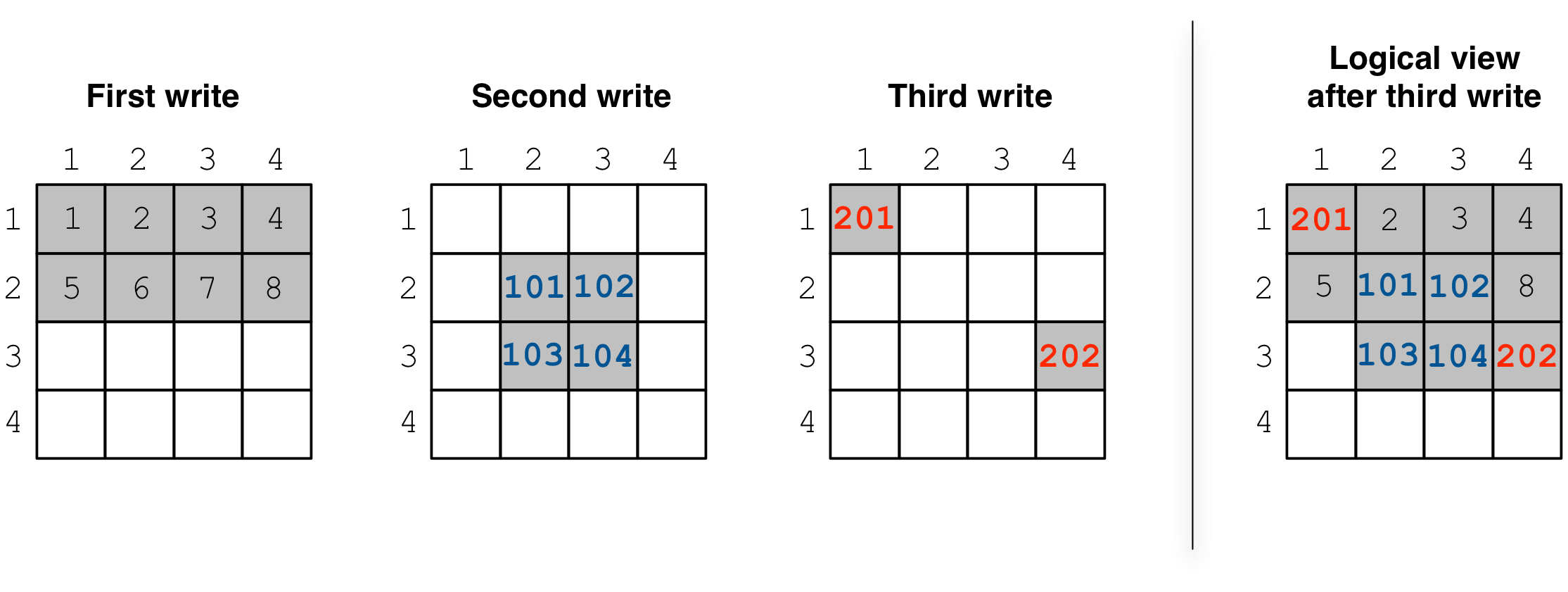
Consider the example in the code listing at the beginning of this tutorial.
This example creates a 4x4 array with 2x2 space tiling, and
performs three separate write operations. The figure below depicts
the cells written in each operation, as well as the collective logical
view of the array.
After compiling and running the program, we see that the array directory contains three subdirectories with weird names:
C++
$ g++ -std=c++11 fragments_consolidation.cc -o fragments_consolidation_cpp -ltiledb
$ ./fragments_consolidation_cpp
Cell (1, 1) has data 201
Cell (1, 2) has data 2
Cell (1, 3) has data 3
Cell (1, 4) has data 4
Cell (2, 1) has data 5
Cell (2, 2) has data 101
Cell (2, 3) has data 102
Cell (2, 4) has data 8
Cell (3, 1) has data -2147483648
Cell (3, 2) has data 103
Cell (3, 3) has data 104
Cell (3, 4) has data 202
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
$ ls -l fragments_consolidation_array/
total 8
drwx------ 4 stavros staff 128 Jun 25 16:23 __1561494215438_1561494215438_f9041c73e04e4cb2b52734f1183508f4
drwx------ 4 stavros staff 128 Jun 25 16:23 __1561494215452_1561494215452_13a7d76455cc44fc893c650270d26ccf
drwx------ 5 stavros staff 160 Jun 25 16:23 __1561494215467_1561494215467_317c5aa1f6eb4e6880f3fda660b86507
-rwx------ 1 stavros staff 149 Jun 25 16:23 __array_schema.tdb
-rwx------ 1 stavros staff 0 Jun 25 16:23 __lock.tdb
Python
$ python fragments_consolidation.py
Cell (1, 1) has data 201
Cell (1, 2) has data 2
Cell (1, 3) has data 3
Cell (1, 4) has data 4
Cell (2, 1) has data 5
Cell (2, 2) has data 101
Cell (2, 3) has data 102
Cell (2, 4) has data 8
Cell (3, 1) has data -2147483648
Cell (3, 2) has data 103
Cell (3, 3) has data 104
Cell (3, 4) has data 202
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
$ ls -l fragments_consolidation_array/
total 8
drwx------ 4 stavros staff 128 Jun 25 16:23 __1561494215438_1561494215438_f9041c73e04e4cb2b52734f1183508f4
drwx------ 4 stavros staff 128 Jun 25 16:23 __1561494215452_1561494215452_13a7d76455cc44fc893c650270d26ccf
drwx------ 5 stavros staff 160 Jun 25 16:23 __1561494215467_1561494215467_317c5aa1f6eb4e6880f3fda660b86507
-rwx------ 1 stavros staff 149 Jun 25 16:23 __array_schema.tdb
-rwx------ 1 stavros staff 0 Jun 25 16:23 __lock.tdb
Each subdirectory corresponds to a fragment, i.e., to an array snapshot containing the cells written in a write operation. How can we tell which fragment corresponds to which write? In this example, this can be easily derived from the fragment name. The name has the following format:
__<timestamp>_<timestamp>_<uuid>
The UUID is
a unique identifier, specific to a process-thread pair. In a later tutorial
we will explain that this enables concurrent threads/processes writing
to the same array. The timestamp records the time
when the fragment got created. Inspecting the fragment names, we derive that
__1561494215438_1561494215438_f9041c73e04e4cb2b52734f1183508f4
corresponds to the first write,
__1561494215452_1561494215452_13a7d76455cc44fc893c650270d26ccf to the
second, and __1561494215467_1561494215467_317c5aa1f6eb4e6880f3fda660b86507
to the third, reading the fragment timestamps in ascending order.
There are two takeaways so far: (i) every fragment is immutable, i.e., a subsequent write operation never overwrites a file of a previously created fragment, and (ii) during a read operation, TileDB logically superimposes every fragment on top of the previous one (chronologically), “overwriting” any common cells. Also note that TileDB has an intelligent internal algorithm for doing this efficiently.
Another interesting feature in TileDB is that each fragment directory is standalone. This means that you can simply remove any subdirectory, and TileDB will function properly as if the write that created that subdirectory never happened. Try out the code below, which checks what happens each time a different fragment is deleted:
C++
$ cp -R fragments_consolidation/ temp
$ rm -rf fragments_consolidation/__1561494215438_1561494215438_f9041c73e04e4cb2b52734f1183508f4
$ ./fragments_consolidation_cpp
Cell (1, 1) has data 201
Cell (1, 2) has data -2147483648
Cell (1, 3) has data -2147483648
Cell (1, 4) has data -2147483648
Cell (2, 1) has data -2147483648
Cell (2, 2) has data 101
Cell (2, 3) has data 102
Cell (2, 4) has data -2147483648
Cell (3, 1) has data -2147483648
Cell (3, 2) has data 103
Cell (3, 3) has data 104
Cell (3, 4) has data 202
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
$ rm -rf fragments_consolidation
$ cp -R temp fragments_consolidation
$ rm -rf fragments_consolidation/__1561494215452_1561494215452_13a7d76455cc44fc893c650270d26ccf
$ ./fragments_consolidation_cpp
Cell (1, 1) has data 201
Cell (1, 2) has data 2
Cell (1, 3) has data 3
Cell (1, 4) has data 4
Cell (2, 1) has data 5
Cell (2, 2) has data 6
Cell (2, 3) has data 7
Cell (2, 4) has data 8
Cell (3, 1) has data -2147483648
Cell (3, 2) has data -2147483648
Cell (3, 3) has data -2147483648
Cell (3, 4) has data 202
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
$ rm -rf fragments_consolidation
$ cp -R temp fragments_consolidation
$ rm -rf fragments_consolidation/__1561494215467_1561494215467_317c5aa1f6eb4e6880f3fda660b86507
$ ./fragments_consolidation_cpp
Cell (1, 1) has data 1
Cell (1, 2) has data 2
Cell (1, 3) has data 3
Cell (1, 4) has data 4
Cell (2, 1) has data 5
Cell (2, 2) has data 101
Cell (2, 3) has data 102
Cell (2, 4) has data 8
Cell (3, 1) has data -2147483648
Cell (3, 2) has data 103
Cell (3, 3) has data 104
Cell (3, 4) has data -2147483648
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
Python
$ cp -R fragments_consolidation/ temp
$ rm -rf fragments_consolidation/__1561494215438_1561494215438_f9041c73e04e4cb2b52734f1183508f4
$ python fragments_consolidation.py
Cell (1, 1) has data 201
Cell (1, 2) has data -2147483648
Cell (1, 3) has data -2147483648
Cell (1, 4) has data -2147483648
Cell (2, 1) has data -2147483648
Cell (2, 2) has data 101
Cell (2, 3) has data 102
Cell (2, 4) has data -2147483648
Cell (3, 1) has data -2147483648
Cell (3, 2) has data 103
Cell (3, 3) has data 104
Cell (3, 4) has data 202
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
$ rm -rf fragments_consolidation
$ cp -R temp fragments_consolidation
$ rm -rf fragments_consolidation/__1561494215452_1561494215452_13a7d76455cc44fc893c650270d26ccf
$ python fragments_consolidation.py
Cell (1, 1) has data 201
Cell (1, 2) has data 2
Cell (1, 3) has data 3
Cell (1, 4) has data 4
Cell (2, 1) has data 5
Cell (2, 2) has data 6
Cell (2, 3) has data 7
Cell (2, 4) has data 8
Cell (3, 1) has data -2147483648
Cell (3, 2) has data -2147483648
Cell (3, 3) has data -2147483648
Cell (3, 4) has data 202
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
$ rm -rf fragments_consolidation
$ cp -R temp fragments_consolidation
$ rm -rf fragments_consolidation/__1561494215467_1561494215467_317c5aa1f6eb4e6880f3fda660b86507
$ python fragments_consolidation.py
Cell (1, 1) has data 1
Cell (1, 2) has data 2
Cell (1, 3) has data 3
Cell (1, 4) has data 4
Cell (2, 1) has data 5
Cell (2, 2) has data 101
Cell (2, 3) has data 102
Cell (2, 4) has data 8
Cell (3, 1) has data -2147483648
Cell (3, 2) has data 103
Cell (3, 3) has data 104
Cell (3, 4) has data -2147483648
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
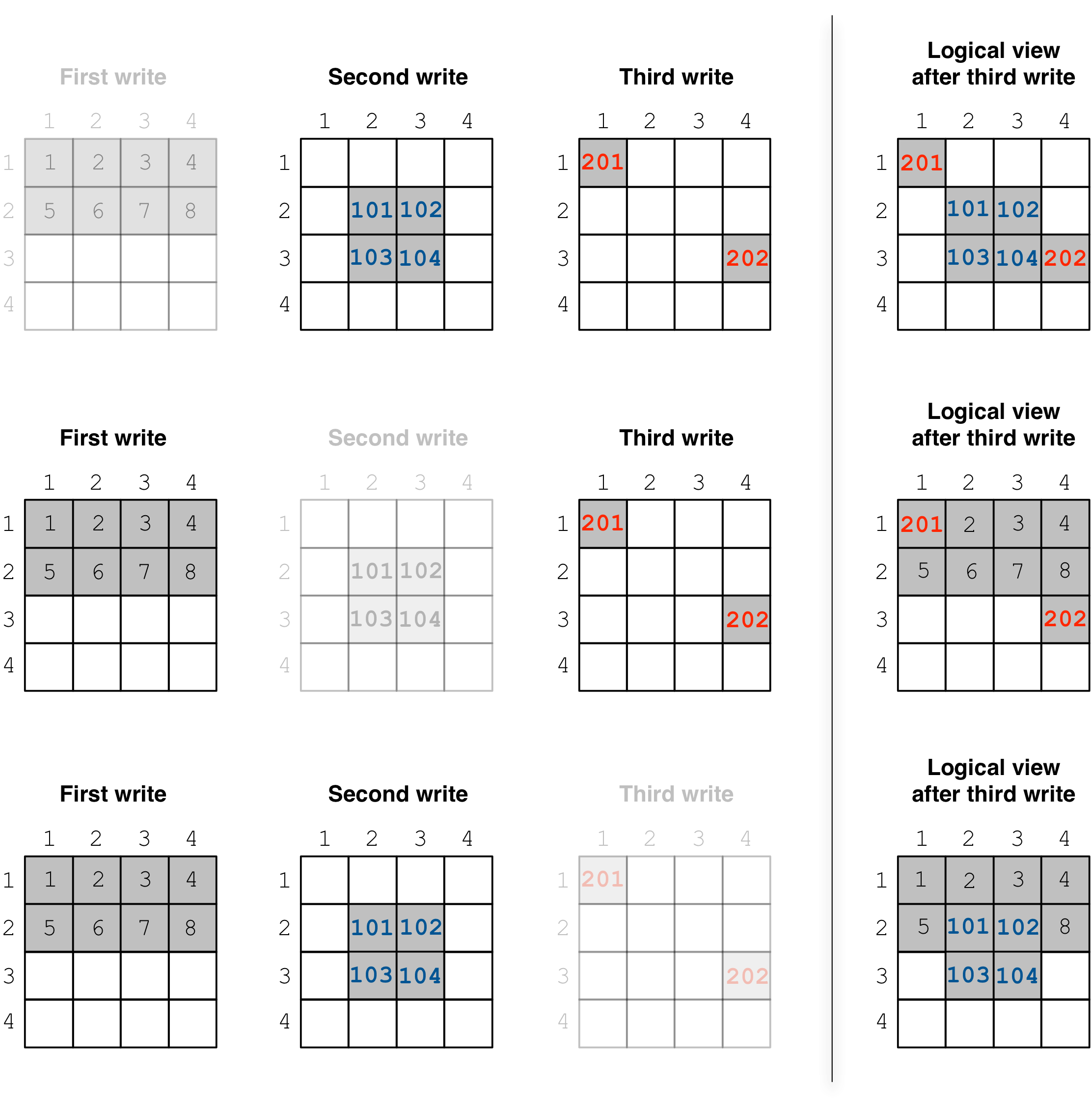
This is also illustrated in the figure below, which shows the array logical view after removing each of the three fragments.
TileDB knows how to recognize a fragment through file
__fragment_metadata.tdb stored in the fragment directory.
This file also makes the fragment self-contained, as it stores all
necessary data that TileDB needs when processing read queries.
Dense vs. sparse fragments¶
A fragment can be dense or sparse. Simply stated, a sparse fragment
stores the explicit coordinates of the non-empty cells in a file
__coords.tdb, whereas a dense fragment is missing this file.
A dense array can have both dense and sparse fragments (since we
explained in an earlier tutorial that you can submit sparse writes
to a dense array), whereas a sparse array can have only sparse fragments
(there is no notion of a dense write in a sparse array). In the
example above, the first two writes create dense fragments, whereas
the third write creates a sparse fragment.
Consolidation¶
The presence of numerous fragments may impact the TileDB read performance. This is because many fragments would lead to numerous fragment metadata files being loaded to main memory from storage. Moreover, they could prevent TileDB from applying certain internal optimizations that work well with fewer fragments.
To mitigate this problem, TileDB has a consolidation feature, which allows you to merge the existing fragments into a single one. Consolidation is thread-/process-safe and can be done in the background while you continue reading from the array without being blocked. Consolidation is done with a simple command (note that you need to put this in a separate thread/process if you wish to make it non-blocking, as it is blocking by default):
C++
Context ctx;
Array::consolidate(ctx, array_name);
Python
tiledb.consolidate(array_name)
Rerunning the above example as shown below (providing consolidate as input
to the program) consolidates the three fragments into one before reading.
C++
$ ./fragments_consolidation_cpp consolidate
Cell (1, 1) has data 201
Cell (1, 2) has data 2
Cell (1, 3) has data 3
Cell (1, 4) has data 4
Cell (2, 1) has data 5
Cell (2, 2) has data 101
Cell (2, 3) has data 102
Cell (2, 4) has data 8
Cell (3, 1) has data -2147483648
Cell (3, 2) has data 103
Cell (3, 3) has data 104
Cell (3, 4) has data 202
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
$ ls -l fragments_consolidation_array/
total 8
drwx------ 4 stavros staff 128 Jun 25 16:28 __1561494215438_1561494215467_1bc203276a1a42c29eb4358325a0f228
-rwx------ 1 stavros staff 149 Jun 25 16:23 __array_schema.tdb
-rwx------ 1 stavros staff 0 Jun 25 16:23 __lock.tdb
$ ls -l fragments_consolidation_array/__1561494215438_1561494215467_1bc203276a1a42c29eb4358325a0f228/
total 16
-rwx------ 1 stavros staff 613 Jun 25 16:28 __fragment_metadata.tdb
-rwx------ 1 stavros staff 144 Jun 25 16:28 a.tdb
Python
$ python fragments_consolidation.py consolidate
Cell (1, 1) has data 201
Cell (1, 2) has data 2
Cell (1, 3) has data 3
Cell (1, 4) has data 4
Cell (2, 1) has data 5
Cell (2, 2) has data 101
Cell (2, 3) has data 102
Cell (2, 4) has data 8
Cell (3, 1) has data -2147483648
Cell (3, 2) has data 103
Cell (3, 3) has data 104
Cell (3, 4) has data 202
Cell (4, 1) has data -2147483648
Cell (4, 2) has data -2147483648
Cell (4, 3) has data -2147483648
Cell (4, 4) has data -2147483648
$ ls -l fragments_consolidation_array/
total 8
drwx------ 4 stavros staff 128 Jun 25 16:28 __1561494215438_1561494215467_1bc203276a1a42c29eb4358325a0f228
-rwx------ 1 stavros staff 149 Jun 25 16:23 __array_schema.tdb
-rwx------ 1 stavros staff 0 Jun 25 16:23 __lock.tdb
$ ls -l fragments_consolidation_array/__1561494215438_1561494215467_1bc203276a1a42c29eb4358325a0f228/
total 16
-rwx------ 1 stavros staff 613 Jun 25 16:28 __fragment_metadata.tdb
-rwx------ 1 stavros staff 144 Jun 25 16:28 a.tdb
As expected, the result is the same as before. However, listing the contents of the array we now see a single fragment. This fragment merges the data of the three writes. We make two observations. The name format is:
__<timestamp_first>_<timestamp_last>_<uuid>
Here timestamp_first is the timestamp of the first fragment that was consolidated (in the chronological order) and timestamp_last the timestamp of the last fragment that was consolidated. In general, TileDB always uses the first timestamp in the fragment name to chronologically sort the fragments during the reads.
The second observation is that the merged fragment is dense (notice that
__coords.tdb is missing). Upon consolidation, TileDB calculates the
subdomain that stores only non-empty cells. In this example, this subdomain
happens to be [1,3], [1,4] (in the general case, the subdomain may be much
smaller than the entire domain). Then it materializes this subdomain
in a dense fragment, i.e., it stores the special fill value for every
empty cell. This is shown in the figure below, and is also evident by
the size of a.tdb, which now stores 64 bytes, i.e., 16 integer values.

Note that the case of consolidating sparse arrays is similar. The only difference is that, since a sparse array can have only sparse fragments, the resulting merged fragment will also be sparse (without extra empty cell materialization required).
Warning
Currently, consolidation process-safety is not guaranteed on S3. This is due to S3’s eventual consistency model, which does not allow us to exclusively “lock” an array when consolidation takes place (TileDB is using filelocking that works well on strongly consistent filesystems). We are working on a solution that will appear in a future release. Until then, make sure to avoid reading the array when it is being consolidated.
Fragments and performance¶
Since TileDB creates a new fragment per write operation, the write performance depends only on the new cells being written and is unaffected by the number of existing fragments. However, the number of fragments may affect the overall read performance. In cases where there are numerous fragments produced, you should use the consolidation feature that enables you to merge multiple fragments in a single one. The consolidation performance naturally depends on the number and size of fragments being consolidated. There are many ways to improve consolidation (and overall ingestion/update) performance. See Advanced Consolidation for more details on tuning the consolidation process.