Multi-attribute Arrays¶
In this tutorial we will learn how to add multiple attributes to TileDB arrays. We will focus only on dense arrays, as everything you learn here applies to sparse arrays as well in a straightforward manner. It is recommended to read the tutorial on dense arrays first.
Program |
Links |
|
|

Basic concepts and definitions¶
Multiple attributes
TileDB enables you to store more than one value per cell via the concept of attributes. You have the flexibility to define an arbitrary number of attributes, potentially each of a different type, in the array schema.
Fixed-length attributes
Here we will cover fixed-length attributes, i.e., attributes whose values consume a fixed amount of space. Fixed-length attributes could be of a primitive data type (e.g.,
int32orchar), or specify a vector of a fixed number of primitive data type values.Note
TileDB currently does not support user-defined datatypes (such as structs). However, this functionality will be added soon.
Attribute subselection
Although an array may have many attributes, the user may be interested in reading just a subset of attribute values. TileDB enables you to subselect on the array attributes upon read queries.
Columnar format
TileDB adopts the so-called columnar format, i.e., it stores the cell values along each attribute in a separate file. This leads to very efficient attribute subselection (as only the values of the attributes you are interested in are fetched from storage, without reading any values from irrelevant attributes), as well as more effective compression (to be covered in a later tutorial).
Creating a multi-attribute array¶
This is similar to what we covered in the simple dense array example. The only
difference is that we add two attributes to the array schema instead of one,
namely a1 that stores characters, and a2 that stores floats. Notice
however that a2 is defined to store two float values per cell.
C++
schema.add_attribute(Attribute::create<char>(ctx, "a1"));
schema.add_attribute(Attribute::create<float[2]>(ctx, "a2"));
Python
schema = tiledb.ArraySchema(domain=dom, sparse=False,
attrs=[tiledb.Attr(name="a1", dtype=np.uint8),
tiledb.Attr(name="a2",
dtype=np.dtype([("", np.float32), ("", np.float32)]))])
We use a np.uint8 to store the character value in a1.
Note
In the current version of TileDB, once an array has been created, you cannot modify the array schema. This means that it is not currently possible to add or remove attributes to an already existing array.
Writing to the array¶
Writing is similar to the simple dense array example. The difference here is that
we need to prepare two data buffers (one for a1 and one for a2).
Note that there should be a one-to-one correspondence
between the values of a1 and a2 in the buffers; for instance, value
1 in data_a1 is associated with value (1.1, 1.2) in data_a2
(recall each cell stores two floats on a2), 2 in data_a1
with (2.1, 2.2) in data_a2, etc.
C++
std::vector<char> data_a1 = {
'a', 'b', 'c', 'd',
'e', 'f', 'g', 'h',
'i', 'j', 'k', 'l',
'm', 'n', 'o', 'p'};
std::vector<float> data_a2 = {
1.1f, 1.2f, 2.1f, 2.2f, 3.1f, 3.2f, 4.1f,
4.2f, 5.1f, 5.2f, 6.1f, 6.2f, 7.1f, 7.2f,
8.1f, 8.2f, 9.1f, 9.2f, 10.1f, 10.2f, 11.1f,
11.2f, 12.1f, 12.2f, 13.1f, 13.2f, 14.1f, 14.2f,
15.1f, 15.2f, 16.1f, 16.2f};
Context ctx;
Array array(ctx, array_name, TILEDB_WRITE);
Query query(ctx, array);
query.set_layout(TILEDB_ROW_MAJOR)
.set_buffer("a1", data_a1)
.set_buffer("a2", data_a2);
query.submit();
array.close();
Python
with tiledb.DenseArray(array_name, mode='w') as A:
data_a1 = np.array((list(map(ord, ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h',
'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p']))))
data_a2 = np.array(([(1.1, 1.2), (2.1, 2.2), (3.1, 3.2), (4.1, 4.2),
(5.1, 5.2), (6.1, 6.2), (7.1, 7.2), (8.1, 8.2),
(9.1, 9.2), (10.1, 10.2), (11.1, 11.2), (12.1, 12.2),
(13.1, 13.2), (14.1, 14.2), (15.1, 15.2), (16.1, 16.2)]),
dtype=[("", np.float32), ("", np.float32)])
A[:, :] = {"a1": data_a1, "a2": data_a2}
Warning
During writing, you must provide a value for all attributes for the cells being written, otherwise an error will be thrown.
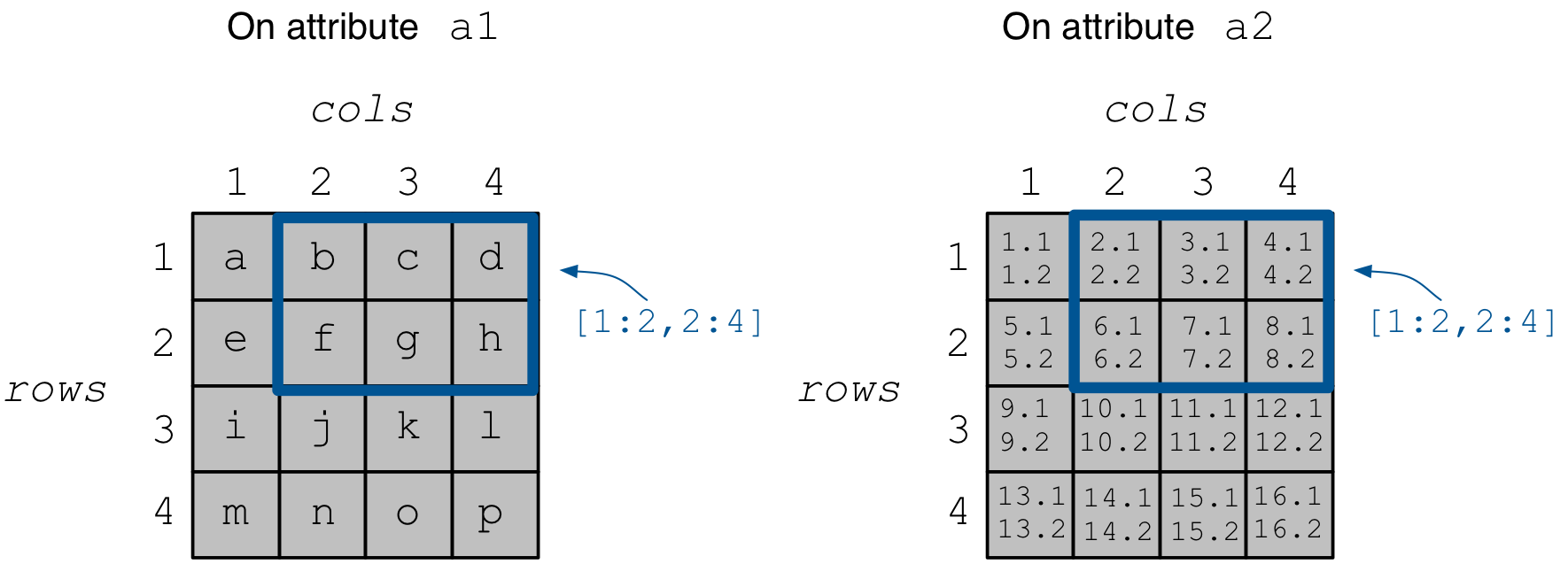
The array on disk now stores the written data. The resulting array is depicted in the figure below.
Reading from the array¶
We focus on subarray [1,2], [2,4].
C++
Reading is similar to the simple dense array example. The difference here
is that we need to allocate two buffers (one for a1 and one for a2)
and set to the query object. Knowing that the result consists of 6 cells,
we allocate 6 character elements for data_a1 and 12 float elements for
data_a2, since a2 stores two floats per cell.
const std::vector<int> subarray = {1, 2, 2, 4};
std::vector<char> data_a1(6);
std::vector<float> data_a2(12);
Context ctx;
Array array(ctx, array_name, TILEDB_READ);
Query query(ctx, array);
query.set_subarray(subarray)
.set_layout(TILEDB_ROW_MAJOR)
.set_buffer("a1", data_a1)
.set_buffer("a2", data_a2);
query.submit();
array.close();
Now data_a1 holds the result cell values on attribute a1 and
data_a2 the results on a2, which we can print simply like:
for (int i = 0; i < 6; ++i)
std::cout << "a1: " << data_a1[i] << ", a2: (" << data_a2[2 * i] << ","
<< data_a2[2 * i + 1] << ")\n";
Python
Reading is similar to the simple dense array example.
with tiledb.DenseArray(array_name, mode='r') as A:
# Slice only rows 1, 2 and cols 2, 3, 4.
data = A[1:3, 2:5]
Now data["a1"] holds the result cell values on attribute a1 and
data["a2"] the results on a2, which we can print simply like:
a1, a2 = data["a1"].flat, data["a2"].flat
for i, v in enumerate(a1):
print("a1: '%s', a2: (%.1f, %.1f)" % (chr(v), a2[i][0], a2[i][1]))
Subselecting on attributes¶
While you must provide values for all attributes during writes, the same is not true during reads.
C++
If you submit a read query with buffers only for some of
the attributes of an array, only those attributes will be read from disk. For example,
if we wish to retrieve the values only on a1, we set only buffer data_a1
to the query object (i.e., omitting data_a2):
const std::vector<int> subarray = {1, 2, 2, 4};
std::vector<char> data_a1(6);
Context ctx;
Array array(ctx, array_name, TILEDB_READ);
Query query(ctx, array);
query.set_subarray(subarray)
.set_layout(TILEDB_ROW_MAJOR)
.set_buffer("a1", data_a1);
query.submit();
array.close();
Python
If you submit a read query with the alternative .query() syntax, you can specify
a list of attribute names. Only those attributes will be read from disk. For example,
if we wish to retrieve the values only on a1, we list only a1
to the query method (i.e., omitting a2):
with tiledb.DenseArray(array_name, mode='r') as A:
data = A.query(attrs=["a1"])[1:3, 2:5]
If you compile and run the example of this tutorial as shown below, you should see the following output:
C++
$ g++ -std=c++11 multi_attribute.cc -o multi_attribute -ltiledb
$ ./multi_attribute
Reading both attributes a1 and a2:
a1: b, a2: (2.1,2.2)
a1: c, a2: (3.1,3.2)
a1: d, a2: (4.1,4.2)
a1: f, a2: (6.1,6.2)
a1: g, a2: (7.1,7.2)
a1: h, a2: (8.1,8.2)
Subselecting on attribute a1:
a1: b
a1: c
a1: d
a1: f
a1: g
a1: h
Python
$ python multi_attribute.py
Reading both attributes a1 and a2:
a1: 'b', a2: (2.1, 2.2)
a1: 'c', a2: (3.1, 3.2)
a1: 'd', a2: (4.1, 4.2)
a1: 'f', a2: (6.1, 6.2)
a1: 'g', a2: (7.1, 7.2)
a1: 'h', a2: (8.1, 8.2)
Subselecting on attribute a1:
a1: 'b'
a1: 'c'
a1: 'd'
a1: 'f'
a1: 'g'
a1: 'h'
On-disk structure¶
Let us look at the contents of the array of this example on disk.
$ ls -l multi_attribute_array/
total 8
drwx------ 5 stavros staff 160 Jun 25 15:34 __1561491299419_1561491299419_fcb0ee91899142baad8a08049c0e2319
-rwx------ 1 stavros staff 159 Jun 25 15:34 __array_schema.tdb
-rwx------ 1 stavros staff 0 Jun 25 15:34 __lock.tdb
$ ls -l multi_attribute_array/__1561491299419_1561491299419_fcb0ee91899142baad8a08049c0e2319/
total 24
-rwx------ 1 stavros staff 939 Jun 25 15:34 __fragment_metadata.tdb
-rwx------ 1 stavros staff 36 Jun 25 15:34 a1.tdb
-rwx------ 1 stavros staff 148 Jun 25 15:34 a2.tdb
TileDB created two separate attribute files in fragment subdirectory
__1561491299419_1561491299419_fcb0ee91899142baad8a08049c0e2319:
a1.tdb that stores the cell values
on attribute a1 (the file size is 16 bytes, equal to the size
required for storing 16 1-byte characters, plus 20 bytes of metadata overhead),
and a2.tdb that stores the cell
values on attribute a2 (the file size is 128 bytes, equal to the
size required for storing 32 4-byte floats, recalling that each cell stores
two floats, plus the 20 bytes of metadata).