Writing Sparse Arrays¶
In this tutorial you will learn how to write to sparse arrays. It is highly recommended that you read the tutorials on sparse arrays and tiling first.
Program |
Links |
|
|
|
|
|
|

Basic concepts and definitions¶
Query
Writing to TileDB arrays is performed by creating and submitting query objects (the term is adopted from the domain of Databases). The query carries the user buffers that contain the cell values to be written, along with the layout of the values in the buffers.
Query layout
The query layout determines the way the user provides the cell values to be written. TileDB supports two layouts for writing in sparse arrays.
Updates
Updates in TileDB are simple write operations. TileDB does not perform writes in-place, i.e., it does not overwrite previously created files. Instead, it creates new files, i.e., all files in TileDB are immutable.
Writing to a sparse array¶
Let us revisit the quickstart_sparse example of tutorial Sparse Arrays.
Here is how we wrote to the array:
C++
std::vector<int> coords = {1, 1, 2, 4, 2, 3};
std::vector<int> data = {1, 2, 3};
Context ctx;
Array array(ctx, array_name, TILEDB_WRITE);
Query query(ctx, array, TILEDB_WRITE);
query.set_buffer("a", data)
.set_coordinates(coords)
.set_layout(TILEDB_UNORDERED);
query.submit();
array.close();
After preparing the cell values to be written,
we construct an array object, effectively
“opening” the array, i.e., preparing the array for writes (e.g., this
loads the array schema from persistent storage to main memory). Then we create
a query, specifying that this query will perform writes. Notice that the
query type must be the same in both the array and query object.
(i.e., TILEDB_WRITE in both cases). Next, we set
the buffers for attribute a and coordinates to the query. These will
be dispatched to TileDB along with the query. Note that the coordinates
are necessary, as these specify exactly in which cells you wish
to write the values.
Subsequently, we set the layout;
this specifies the order in which you stored the cell values in buffers
coords and data. Unordered here means that the cells are not
given in a particular order. TileDB needs this information in order to
sort internally and then store the values along the global
cell order (recall that TileDB always respects the global cell order
when writing the array data in physical storage). In this example
it happens for the given order (row-major) to be the same as the
global order. We will see in later examples that this is not true
in general. For instance, if we had specified a 2x2 space tiling
for the above array, the global order would be (1,1), (2, 3), (2,4).
Below we explain that
TileDB enables you to write also directly in global order, avoiding
the sorting and boosting performance. Finally, we submit the query
and close the array.
Python
# Open the array and write to it.
with tiledb.SparseArray(array_name, mode='w') as A:
# Write some simple data to cells (1, 1), (2, 4) and (2, 3).
I, J = [1, 2, 2], [1, 4, 3]
data = np.array(([1, 2, 3]));
A[I, J] = data
We first create a sparse array object, which “opens” the array
in write mode. This prepares the array for writes, e.g., it
loads the array schema from persistent storage to main memory.
Then we initialize two vectors I and J with the coordinates
we wish to write. Note that each vector holds the coordinates along
each dimension, i.e., I holds the row coordinates and J
the column coordinates. The above code will write to cells
(1,1), (2, 3), (2,4). The coordinates do not need to be sorted
in any particular order, i.e., TileDB always considers the cell
layout as unordered in this example. TileDB will sort internally
the coordinates on the global physical cell layout prior to writing
the values on disk.
Multiple writes / Updates¶
TileDB of course allows you to submit multiple write queries to an array, and a query may update (i.e., modify) previously written values. Consider the example in the figure below, where we perform two writes to the same array.
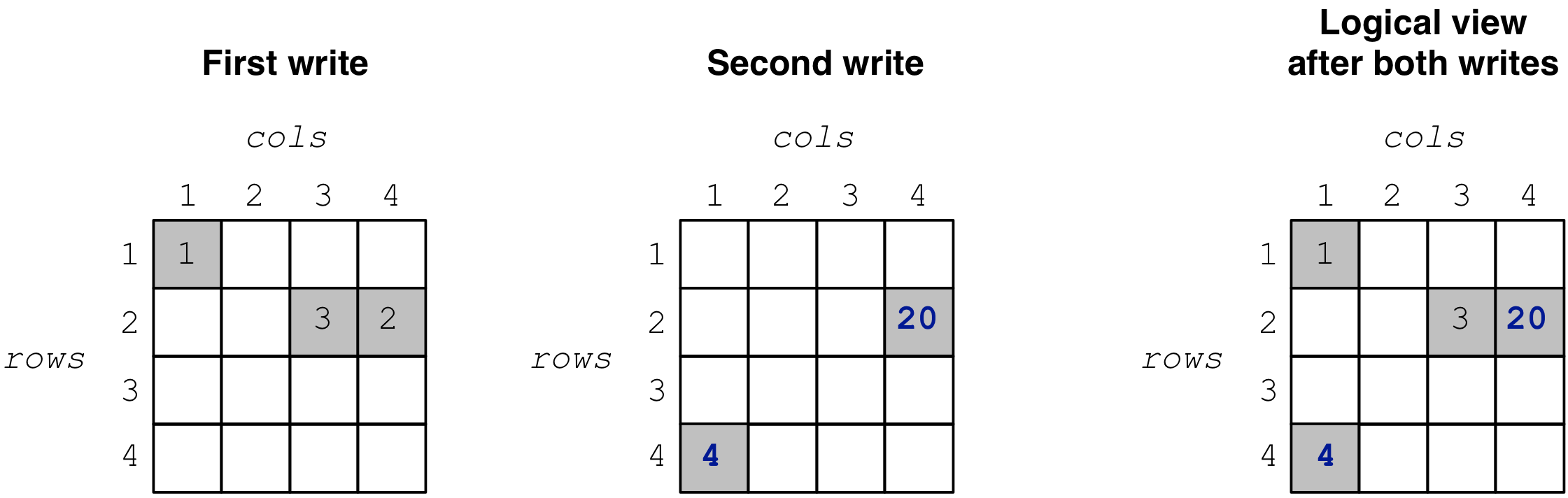
When we read the array, as expected, we get the cells
shown in the collective logical view produced by both writes,
i.e., after cell (4,1) is added and cell (2,4) is modified
in the second write. Running example writing_sparse_multiple, you get
the following:
C++
$ g++ -std=c++11 writing_sparse_multiple.cc -o writing_sparse_multiple_cpp -ltiledb
$ ./writing_sparse_multiple_cpp
Cell (1, 1) has data 1
Cell (2, 3) has data 3
Cell (2, 4) has data 20
Cell (4, 1) has data 4
Python
$ python writing_sparse_multiple.py
Cell (1, 1) has data 1
Cell (2, 3) has data 3
Cell (2, 4) has data 20
Cell (4, 1) has data 4
Let us see how the array directory looks like after the execution of the program:
$ ls -l multiple_writes_sparse_array/
total 8
drwx------ 5 stavros staff 160 Jun 25 15:41 __1561491710236_1561491710236_3eadf863ae0443c7815857d055ed45c7
drwx------ 5 stavros staff 160 Jun 25 15:41 __1561491710249_1561491710249_a94a9605d30049939eb34f7ee6eb4708
-rwx------ 1 stavros staff 153 Jun 25 15:41 __array_schema.tdb
-rwx------ 1 stavros staff 0 Jun 25 15:41 __lock.tdb
$ ls -l multiple_writes_sparse_array/__1561491710236_1561491710236_3eadf863ae0443c7815857d055ed45c7/
total 24
-rwx------ 1 stavros staff 106 Jun 25 15:41 __coords.tdb
-rwx------ 1 stavros staff 611 Jun 25 15:41 __fragment_metadata.tdb
-rwx------ 1 stavros staff 32 Jun 25 15:41 a.tdb
$ ls -l multiple_writes_sparse_array/__1561491710249_1561491710249_a94a9605d30049939eb34f7ee6eb4708/
total 24
-rwx------ 1 stavrospapadopoulos staff 98 Jun 25 15:41 __coords.tdb
-rwx------ 1 stavrospapadopoulos staff 612 Jun 25 15:41 __fragment_metadata.tdb
-rwx------ 1 stavrospapadopoulos staff 28 Jun 25 15:41 a.tdb
Notice that now there are two subdirectories under the array directory. Each subdirectory corresponds to a write operation and is called fragment. We discuss fragments in more detail in a later tutorial. However, what is important here is that the cell values added by different operations create different files and no file is overwritten. You may perceive each write as a separate array (hence, array “fragment”). TileDB is smart enough to understand how (and when!) you created these fragments and provide you with the correct values upon reading.
Note
Every file in TileDB is immutable!
A final remark concerns deletions. Currently, TileDB does not support deletions. If you wish to delete a cell, you will have to essentially set a “dummy” value (that you know how to recognize on your end) to that cell, which will act as a tombstone marking the cell as deleted. We are currently working on a better way of handling deletions, which we will make available in a future release.
Writing in global layout¶
Warning
Currently global writes are not supported in the Python API.
So far we have been using the “unordered” layout when providing the cells to TileDB for writing, which will be the most frequent layout you will use. However, if your cells are already laid out in the global order of your array, TileDB allows you to write them in the global layout. This provides two benefits: (i) you avoid the internal TileDB sorting step, which may result in some performance speedup (TileDB parallelizes sorting internally, but you can still gain if you completely avoid it), and (ii) as we shall see below, writing in global order enables you to submit an arbitrary number of queries, without creating a new fragment each time, but rather always appending to the same fragment. This is useful if you have a very large dataset and you wish to just stream it into a TileDB array, avoiding the creation of numerous subfolders and files.
You set the global layout simply as follows:
C++
query.set_layout(TILEDB_GLOBAL_ORDER);
In the writing_sparse_global example we show you how to slightly
modify quickstart_sparse, such that
you write in global layout instead of unordered, submitting
two write queries instead of one. Here are the two write queries for the same
three cells:
C++
// Submit first query
std::vector<int> coords_1 = {1, 1, 2, 4};
std::vector<int> data_1 = {1, 2};
query.set_buffer("a", data_1).set_coordinates(coords_1);
query.submit();
// Submit second query
std::vector<int> coords_2 = {2, 3};
std::vector<int> data_2 = {3};
query.set_buffer("a", data_2).set_coordinates(coords_2);
query.submit();
Observe that, if the next cell values to be written are stored in different buffers, you need to set those buffers to the query before submitting it.
When writing in global order, TileDB maintains some internal state. This is to allow you to submit successive queries and let TileDB pick up the writing process from where it left off. It is extremely important to flush this state when you are done writing in global order as follows:
C++
query.finalize();
Let us compile and run the program, and then inspect the contents of the array directory:
$ g++ -std=c++11 writing_sparse_global.cc -o writing_sparse_global_cpp -ltiledb
$ ./writing_sparse_global_cpp
Cell (1, 1) has data 1
Cell (2, 3) has data 3
Cell (2, 4) has data 2
$ ls -l global_order_sparse_array/
total 8
drwx------ 5 stavros staff 160 Jun 25 15:44 __1561491885787_1561491885787_eccb5f9e17c54fef90cedf633d47118c
-rwx------ 1 stavros staff 153 Jun 25 15:44 __array_schema.tdb
-rwx------ 1 stavros staff 0 Jun 25 15:44 __lock.tdb
As expected, the array contains the same cells and values as quickstart_sparse.
Moreover, despite the fact that we submitted two write queries, only one
subfolder/fragment got created. This confirms that successive write query
submissions in global order append the cell values to the same
fragment files.
Choosing a layout¶
In the above example, the global order was trivial to determine, because we had
a single 4x4 space tile and the cell order was row-major. This resulted in
a global order that required all cells to be sorted in row-major order.
However, for larger arrays with
finer-grained space tiling, it will generally be non-trivial to manually derive
the global order and provide the cells to TileDB sorted on that order. Therefore,
we expect you to use the unordered layout in the vast majority of your applications.
Just note that TileDB has got your back here, since it performs sorting internally
very efficiently via parallelization, whereas it also provides an efficient fragment
consolidation mechanism in case you create too many fragments (covered in a later tutorial).
Writing and performance¶
As mentioned above, the layout in which you write the cells may affect performance, as writing in the unordered layout involves some internal sorting, which is avoided in the case of global order writes. Moreover, each write in the unordered layout produces a separate fragment. We will soon explain that numerous fragments may impact both the write and read performance. See the Introduction to Performance tutorial for more information about the TileDB performance.